
OpenAI анонсує ChatGPT 4o (Omni) – це нова версія, яка приймає як вхідні дані будь-яку комбінацію тексту, аудіо та зображень та генерує будь-яку комбінацію виходів тексту, аудіо та зображень.
Назва нової версії – ChatGPT 4o, де «o» означає «omni», що є комбінованим словом, яке означає «все».
GPT-4o (Omni)
ChatGPT 4o може реагувати на аудіовхід лише за 232 мілісекунди, із середнім показником 320 мілісекунд, що відповідає часу реакції людини в розмові. Omni відповідає продуктивності GPT-4 Turbo для тексту англійською мовою та коду зі значним покращенням для тексту неанглійськими мовами, а також є набагато швидшим та на 50% дешевшим в API.
Розширена обробка голосу
До GPT-4o користувачі могли використовувати голосовий режим для розмови з ChatGPT із середньою затримкою 2,8 секунди (GPT-3,5) та 5,4 секунди (GPT-4). Щоб досягти цього, голосовий режим є конвеєром із трьох окремих моделей: одна проста модель транскрибує аудіо в текст, GPT-3.5 або GPT-4 приймає текст та виводить текст, а третя проста модель перетворює цей текст назад в аудіо. Цей процес означає, що основне джерело інтелекту, GPT-4, втрачає багато інформації — воно не може безпосередньо спостерігати тон, кілька динаміків або фонові шуми, а також не може виводити сміх, спів або виражати емоції.
За допомогою GPT-4o ми навчили єдину нову наскрізну модель для тексту, зображення та аудіо, тобто всі вхідні та вихідні дані обробляються тією самою нейронною мережею. Оскільки GPT-4o є нашою першою моделлю, яка поєднує в собі всі ці модальності, ми все ще лише дряпаємо поверхню, вивчаючи можливості моделі та її обмеження.
Модельні оцінки
Згідно з традиційними тестами, GPT-4o досягає продуктивності GPT-4 Turbo на рівні тексту, міркувань і кодування, встановлюючи при цьому нові високі водяні знаки для багатомовних, аудіо- та візуальних можливостей.
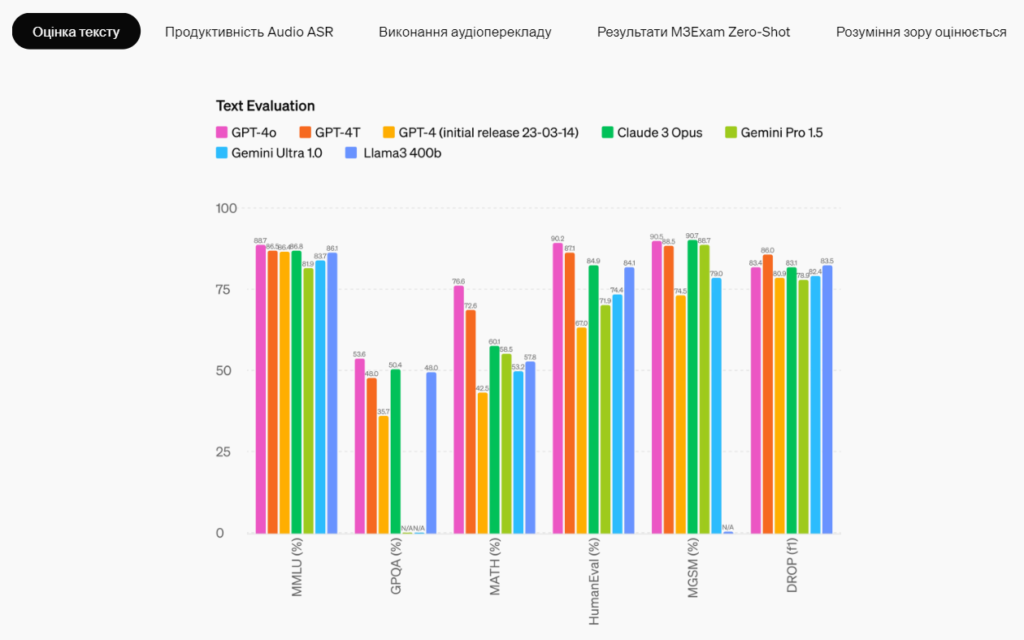
Наразі використання моделі є безплатним для всіх користувачів, а платні користувачі надалі матимуть обсяги обробки, збільшені у 5 разів.
Докладніше про можливості GPT-4o та обмеження моделі — за посиланням вгорі новини.


